- 1. Dropout简介
- 1.1 Dropout出现的原因
- 1.2 什么是Dropout
- 2. Dropout工作原理
- 3. 为什么说Dropout可以解决过拟合?
1. Dropout简介
1.1 Dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout层在神经网络层当中是用来干嘛的呢?它是一种可以用于减少神经网络过拟合的结构。
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
1.2 什么是Dropout
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。
当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
在2012年,Alex、Hinton在其论文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止过拟合。并且,这篇论文提到的AlexNet网络模型引爆了神经网络应用热潮,并赢得了2012年图像识别大赛冠军,使得CNN成为图像分类上的核心算法模型。
随后,又有一些关于Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
从上面的论文中,我们能感受到Dropout在深度学习中的重要性。那么,到底什么是Dropout呢?
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
2. Dropout工作原理
假设下图是我们用来训练的原始神经网络:
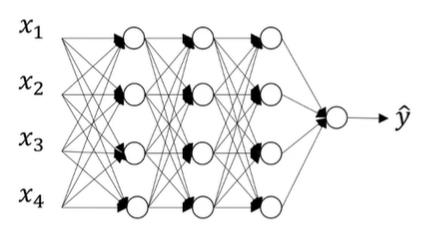
一共有四个输入x_i,一个输出y。Dropout则是在每一个batch的训练当中随机减掉一些神经元,而作为编程者,我们可以设定每一层dropout(将神经元去除的的多少)的概率,在设定之后,就可以得到第一个batch进行训练的结果:
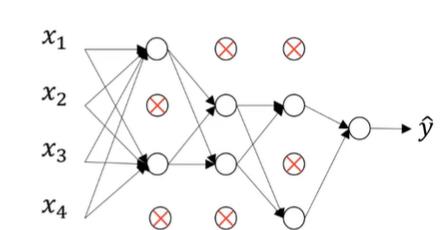
从上图我们可以看到一些神经元之间断开了连接,因此它们被dropout了!dropout顾名思义就是被拿掉的意思,正因为我们在神经网络当中拿掉了一些神经元,所以才叫做dropout层。
在进行第一个batch的训练时,有以下步骤:
1.设定每一个神经网络层进行dropout的概率
2.根据相应的概率拿掉一部分的神经元,然后开始训练,更新没有被拿掉神经元以及权重的参数,将其保留
3.参数全部更新之后,又重新根据相应的概率拿掉一部分神经元,然后开始训练,如果新用于训练的神经元已经在第一次当中训练过,那么我们继续更新它的参数。而第二次被剪掉的神经元,同时第一次已经更新过参数的,我们保留它的权重,不做修改,直到第n次batch进行dropout时没有将其删除。
3. 为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
备注:
这就是dropout层的思想了,为什么dropout能够用于防止过拟合呢?因为约大的神经网络就越有可能产生过拟合,因此我们随机删除一些神经元就可以防止其过拟合了,也就是让我们拟合的结果没那么准确。就如同机器学习里面的L1/L2正则化一样的效果!
那么我们应该对什么样的神经网络层进行dropout的操作呢?很显然是神经元个数较多的层,因为神经元较多的层更容易让整个神经网络进行预测的结果产生过拟合,假设有如下图所示的一个dropou层:
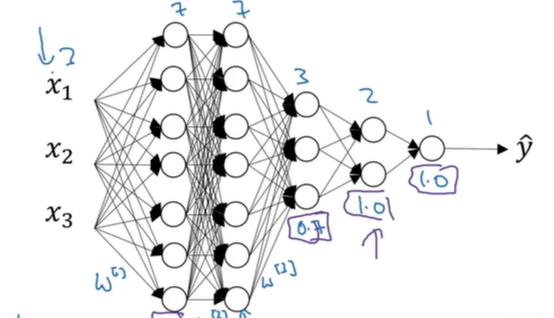
由于隐藏层的第一层和第二层神经元个数较多,容易产生过拟合,因此我们将其加上dropout的结构,而后面神经元个数较少的地方就不用加了!
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/11258.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫