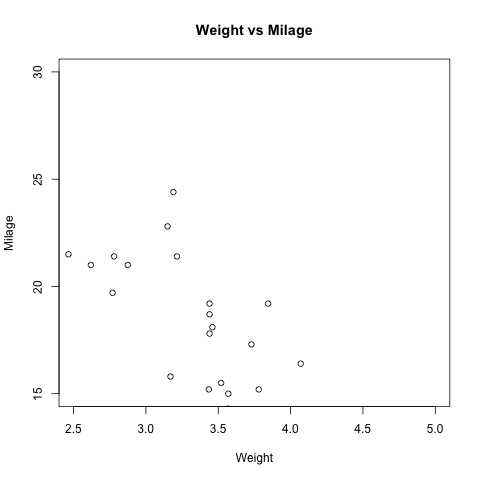
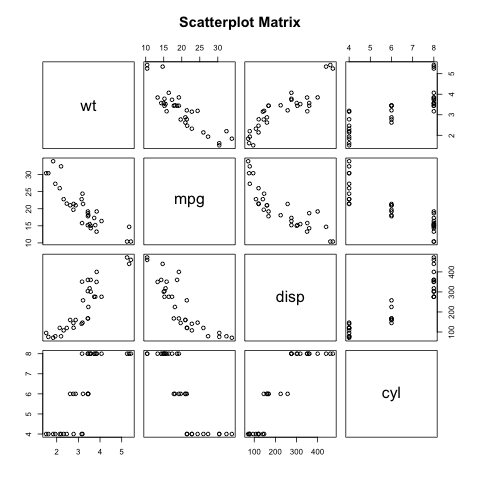
text = "Got tho on super sale. Love it! Cuts my drying time in half Reckon I have had this about a year now,\
at least 7 months. Works great, I use it 5 days a week, blows hot air, doesnt overheat,\
isnt to big, came quick, didnt cost much. Get you one, you will like it.The styling tip does not stay on,\
keeps falling off in the middle of blow drying and then it's too hot to put back"
text = text.lower()
# 将特殊字符替换成为空格
for ch in '!@#$%:^&*()-.;':
text = text.replace(ch, " ")
# 对字符串通过空格进行分割
words = text.split()
counts = {}
for word in words:
if word in counts:
counts[word] = counts[word] + 1
else:
counts[word] = 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
# 输出词频统计的结果
for i in range(3):
word, count = items[i]
if i<2:
print("{0}:{1}".format(word, count))
else:
print("{0}:{1}".format(word, count),end="")
要统计英文词频,可以使用Python中的字典数据结构和字符串操作函数。
下面是一个简单的示例代码,用于统计一个英文文本中每个单词出现的次数:
def word_frequency(text):
# 将文本转换为小写并按空格分割为单词列表
words = text.lower().split()
# 创建一个空字典用于存储单词及其出现次数
frequency = {}
# 遍历单词列表
for word in words:
# 去除单词中的标点符号
word = word.strip(".,!?")
# 如果单词已经在字典中,则将其出现次数加1;否则将单词添加到字典中,并将出现次数设为1
if word in frequency:
frequency[word] += 1
else:
frequency[word] = 1
# 返回字典
return frequency
# 示例用法
text = "This is a sample text. It contains some words, some of which are repeated."
result = word_frequency(text)
print(result)
运行以上代码,输出结果如下:
{'this': 1, 'is': 1, 'a': 1, 'sample': 1, 'text': 1, 'it': 1, 'contains': 1, 'some': 2, 'words': 1, 'of': 1, 'which': 1, 'are': 1, 'repeated': 1}
可以看到,每个单词及其出现次数被存储在一个字典中。
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/12276.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫