页面有一个input file服务器控件,一个div,div是image标签的容器,当点击input file的值改变,我们往div里追加image标签;但当通过js的onchange事件动态获取input file 的路径的时候,发现console.log(path)打印出的路径是被浏览器屏蔽的,
例如:C:\fakepath\file.jpg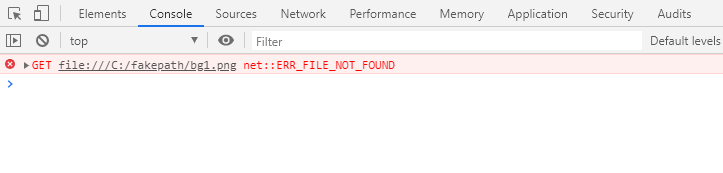
这是由于浏览器的安全机制,input file的路径被fakepath代替,隐藏了真实物理路径。
解决方法
(1)调整浏览器的浏览器安全设置(不推荐,也不合理)。
(2)使用window.URL.createObjectURL()
var url = null;
var fileObj = document.getElementById("aptitude").files[0];
if (window.createObjcectURL != undefined) {
url = window.createOjcectURL(fileObj);
} else if (window.URL != undefined) {
url = window.URL.createObjectURL(fileObj);
} else if (window.webkitURL != undefined) {
url = window.webkitURL.createObjectURL(fileObj);
}
解释:
URL.createObjectURL()方法会根据传入的参数创建一个指向该参数对象的URL,这个URL的生命仅存在于它被创建的这个文档里,新的对象URL指向执行的File对象或Blob对象。
语法:objcetURL = window.URL.createObjectURL(file || blob);
参数:File对象和Blob对象;File对象就是一个文件,比如我用file type=”file”标签来上传文件,那么里面的每个文件都是一个file对象。Blob对象就是二进制数据,比如在XMLHttpRequest里,如果指定requestType为blob,那么得到的返回值也是一个blob对象。 每次调用createObjectURL的时候,一个新的URL对象就被创建了。即使你已经为同一个文件创建过一个URL.,如果你不再需要这个对象,要释放它,需要使用URL.revokeObjectURL()方法.。当页面被关闭,浏览器会自动释放它,但是为了最佳性能和内存使用,当确保不再用得到它的时候,就应该释放它。
(3)使用FileReader.readAsDataURL()
function ii(obj)
var oFReader = new FileReader();
var file = obj.files[0];
oFReader.readAsDataURL(file);
oFReader.onloadend = function (oFRevent) {
src = oFRevent.target.result;
};
}
解释:
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用 File 或 Blob 对象指定要读取的文件或数据。
异步读取指定的Blob中的内容,一旦完成,会返回一个data: URL格式的字符串以表示所读取文件的内容。
window.URL.createObjectURL()和FileReader.readAsDataURL()的区别
返回值
FileReader.readAsDataURL(blob)可以得到一段base64的字符串
URL.createObjectURL(blob)得到的是当前文件的一个内存url
内存使用
FileReader.readAsDataURL(blob)得到一段超长的base64的字符串
URL.createObjectURL(blob)得到的是一个url地址
内存清理
FileReader.readAsDataURL(blob)依照js垃圾回收机制自动从内存中清理
URL.createObjectURL(blob)存在于当前document内,清除方式只有upload()事件或者revokeObjectURL()手动清除
执行方式
FileReader.readAsDataURL(blob)通过回调的方式f返回,异步执行;
URL.createObjectURL(blob) 直接返回,同步执行;
多个文件
FileReader.readAsDataURL(blob)同时处理多个文件时,需要一个文件对应一个FileReader对象;
URL.createObjectURL(blob) 依次返回,没有影响;
总结:
URL.createObjectURL(blob) 得到本地内存容器的URL地址,方便预览,多次使用需要注意手动释放内存的问题,性能优秀。
FileReader.readAsDataURL(blob)胜在直接转为base64格式,可以直接用于业务,无需二次转换格式。
本文来自投稿,不代表125jz立场,如若转载,请注明出处:http://www.125jz.com/4197.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫