存储过程中的参数
MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT,形式如:
CREATE PROCEDURE([[IN |OUT |INOUT ] 参数名 数据类形…])
IN 输入参数:表示该参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值
OUT 输出参数:该值可在存储过程内部被改变,并可返回
INOUT 输入输出参数:调用时指定,并且可被改变和返回
创建一个简单的存储过程:
存储过程proc_adder功能很简单,两个整型输入参数a和b,一个整型输出参数sum,功能就是计算输入参数a和b的结果,赋值给输出参数sum;
-- ----------------------------
-- Procedure structure for `proc_adder`
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_adder`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
BEGIN
#Routine body goes here...
DECLARE c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set sum = a + b;
END
;;
DELIMITER ;
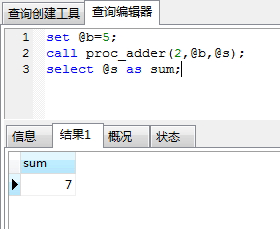
执行以上存储结果,验证是否正确,如下图,结果OK:
set @b=5; call proc_adder(2,@b,@s); select @s as sum;
 存储过程的优势和不足
存储过程的优势和不足
存储过程的优势
- 存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。 通过把处理封装在容易使用的单元中,简化复杂的操作。
- 存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
- 简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。
- 存储过程能实现较快的执行速度。如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
- 存储过程能过减少网络流量。针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
- 存储过程可被作为一种安全机制来充分利用。系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
存储过程的不足
- 不同数据库,语法差别很大,移植困难,换了数据库,需要重新编写;
- 不好管理,把过多业务逻辑写在存储过程不好维护,不利于分层管理,容易混乱,一般存储过程适用于个别对性能要求较高的业务,其它的必要性不是很大;
125jz网原创文章。发布者:江山如画,转载请注明出处:http://www.125jz.com/2947.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫